Deep Dive: Everything you need to know about Finetuning and Merging LLMs
← Head back to all of our AI Engineer World's Fair recaps
Maxime Labonne @maximelabonne / Liquid AI
Watch it on YouTube | AI.Engineer Talk Details
This talk provided a great overview of current techniques in LLM fine-tuning and model merging. The examples of creative merging techniques, like the pass-through method and Franken MoE, were particularly eye-opening and show there's still a lot to explore in this field.
Fine-tuning LLMs
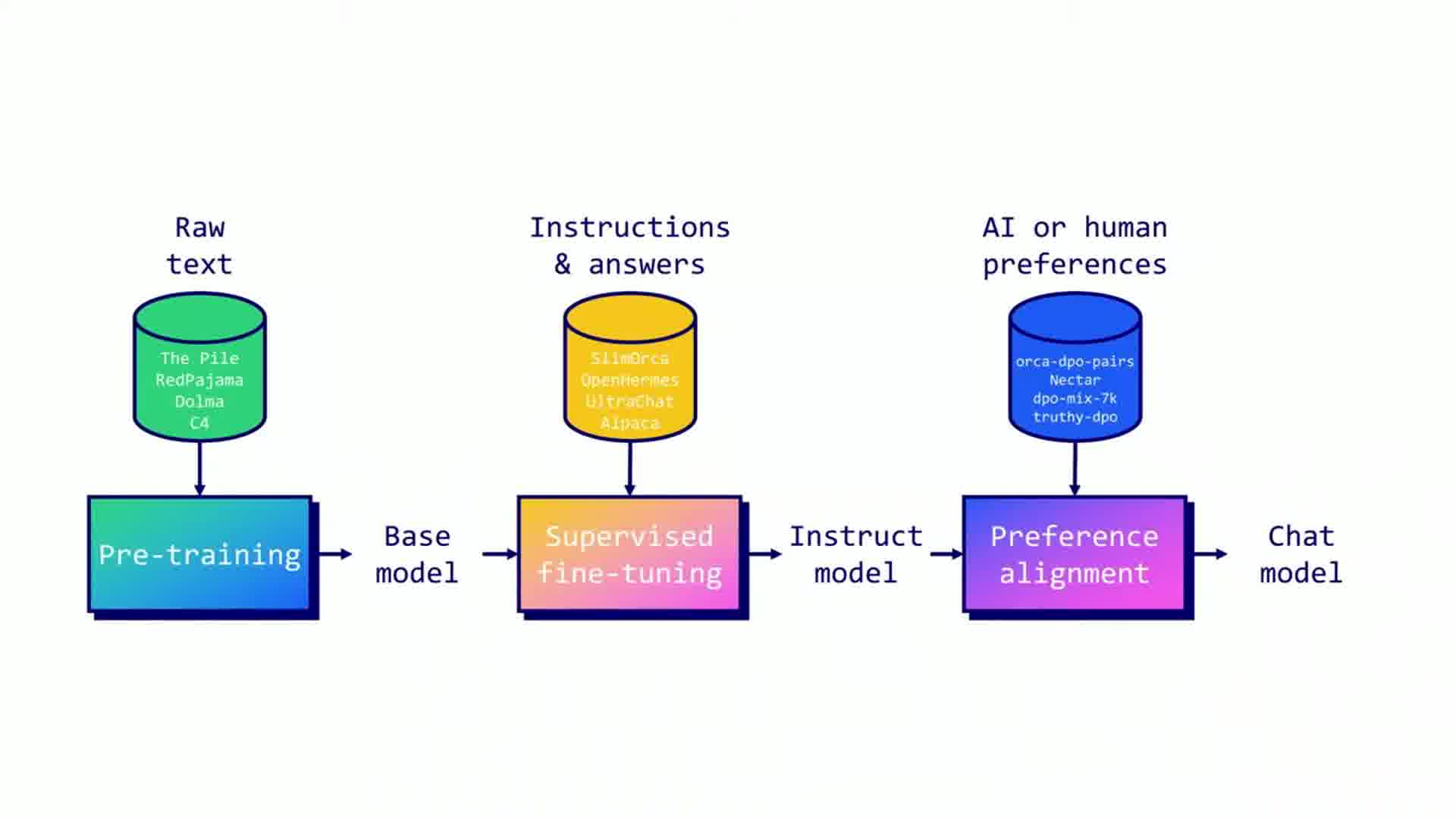
Labon outlined the LLM training lifecycle:
- Pre-training
- Supervised fine-tuning (SFT)
- Preference alignment
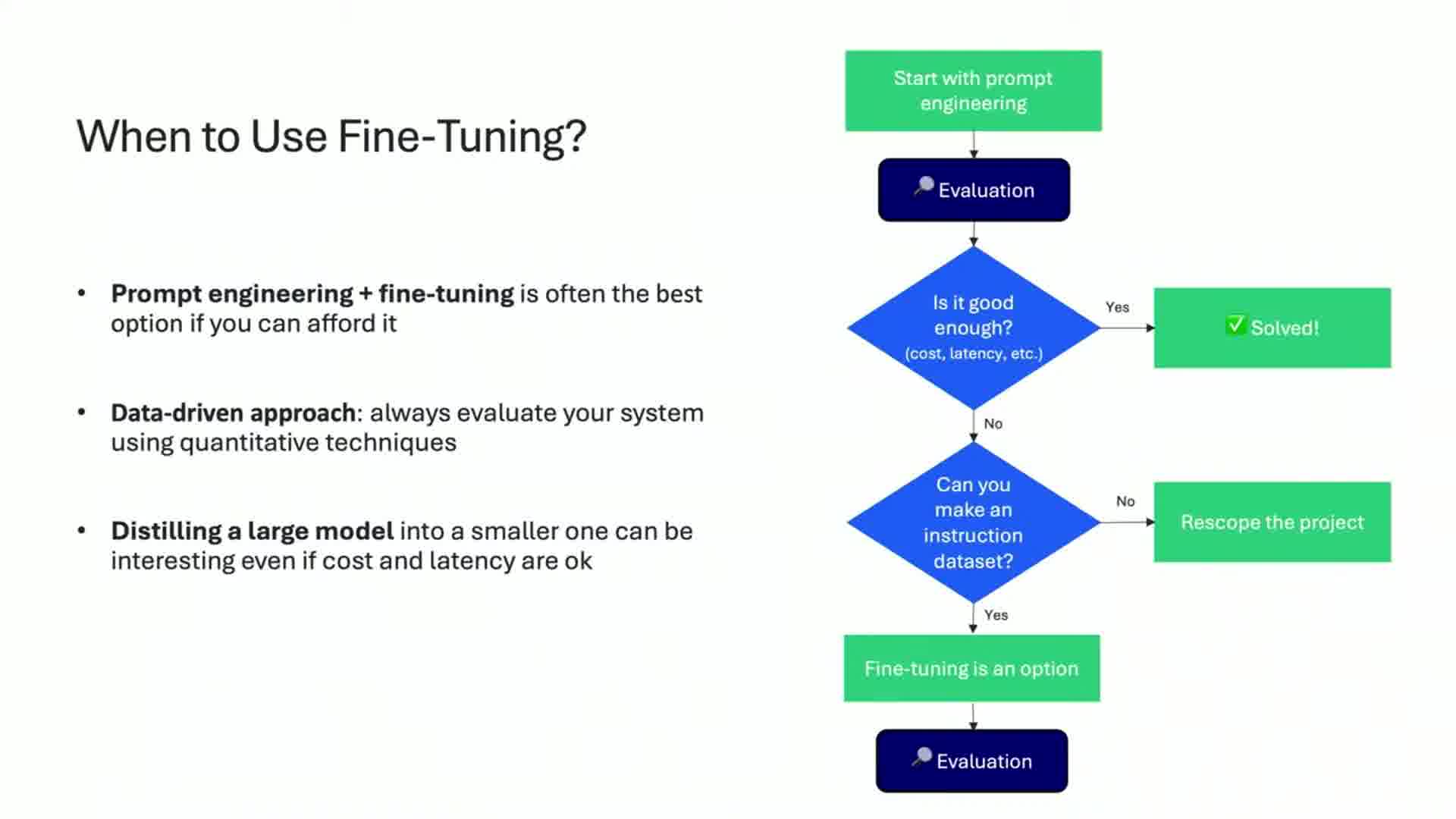
He emphasized the importance of starting with prompt engineering before moving to fine-tuning, and shared a flowchart to help decide when to use each approach.
SFT Techniques
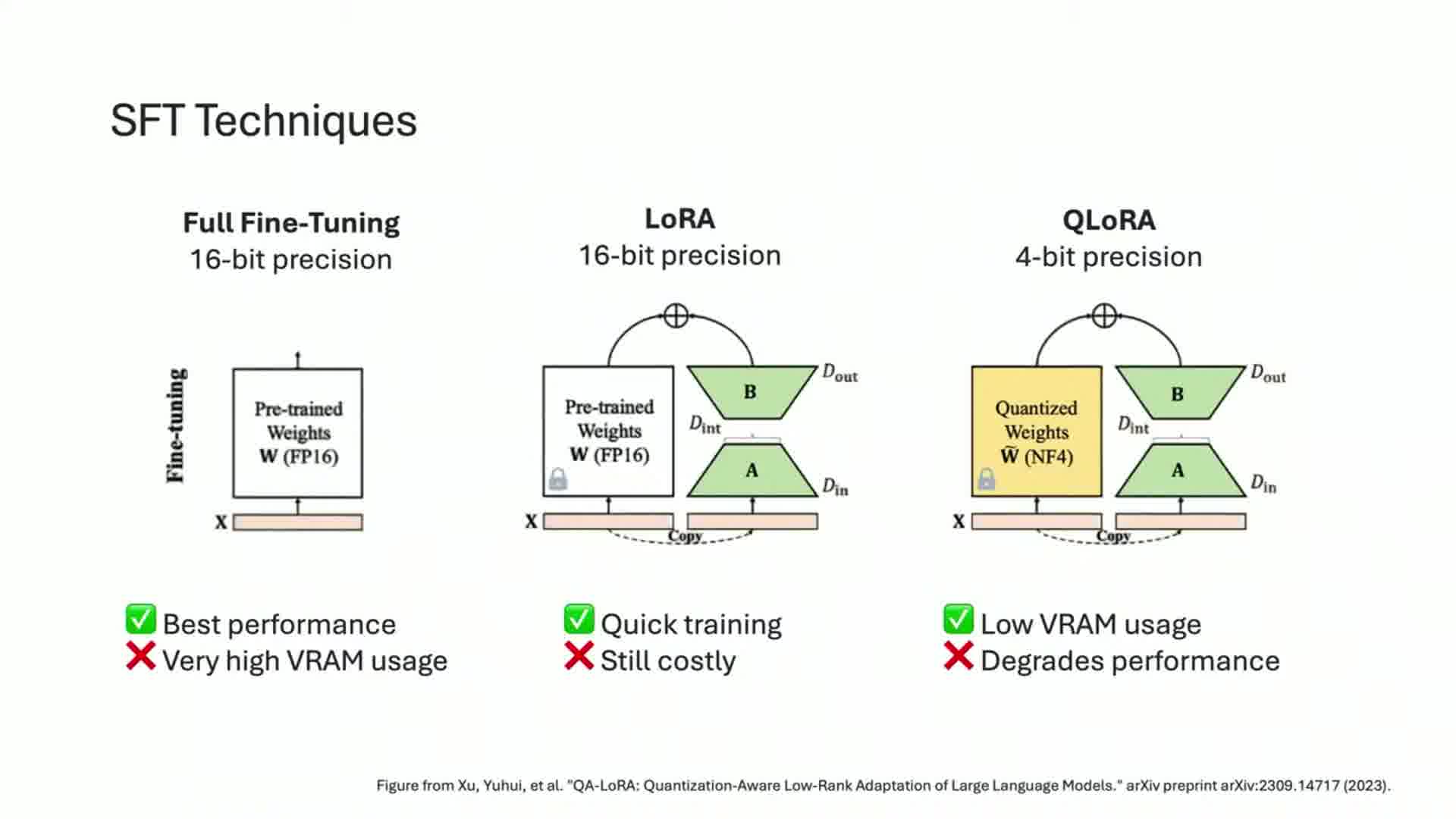
Labon discussed three main SFT techniques:
- Full fine-tuning
- LoRA (Low-Rank Adaptation)
- QLoRA (Quantized LoRA)
He highlighted the trade-offs between performance, efficiency, and DRAM usage for each method.
Creating SFT Datasets

Labon stressed three key features for good SFT datasets:
- Accuracy
- Diversity
- Complexity
He provided a "recipe" for creating datasets, including using open-source datasets, applying filters, and iterative improvement.
Model Merging

This part of the talk was particularly interesting. Labon explained how model merging combines weights from different fine-tuned models without requiring GPUs. He mentioned that merged models dominate the top spots on the OpenLM leaderboard for 7B parameter models.
Merging Techniques

- SLERP (Spherical Linear Interpolation)
- DARE (Debiased Averaged Rank Ensemble)
- Pass-through
- Mixture of Experts (MoE)
The pass-through technique was especially intriguing. Labon shared an example called "Llama 120B Instruct" where he repeated 10 layers of Llama 3 70B Instruct 6 times.
Surprisingly, this model performed well in creative writing tasks without any fine-tuning.
Labon also discussed creating a "Franken MoE" by combining feed-forward network layers from different fine-tuned models with a router. He showed a merge kit config for his "Beyonder" model, which outperformed its source models on various benchmarks.
Resources to Explore
For those interested in diving deeper, Labon mentioned his Large Language Model course on GitHub, which includes notebooks to run some of the code he discussed. I'll definitely be checking that out for more hands-on learning.